重点问题汇总
二、重点问题汇总 #
2.1 数据治理 #
2.1.1、数据治理到底有哪些内容? #
- 组织架构
- 是否要设立CDO
- 关于委员会
- 数据管理专员
- 数据owner
- 认责机制
- 规章制度
- 流程
- 技术
2.1.2、数据治理包括哪些具体活动? #
1、定义数据治理策略
- 制定数据治理策略
- 执行准备情况评估
- 执行发现和业务协调
- 开发组织接触点
2、定义数据治理组织
- 定义数据治理运营框架
- 制定目标、原则和制度
- 承保数据管理项目
- 参与变更管理
- 参与问题管理
- 评估监管合规性要求
3、实施数据治理
- 支持数据标准和程序
- 制定业务术语表
- 与架构组协调
- 支持数据资产评估
4、嵌入数据治理
2.1.3、数据治理的输出物有哪些? #
数据治理策略、数据策略、业务/数据治理策略路线图、数据原则、数据治理制度、流程、运营框架、路线图和实施策略、运营计划、业务术语表等。
2.1.4、数据治理的运营模式? #
运营模式包括:
- 集中式
- 分布式
- 联邦式
2.1.5、数据治理的考核目标? #
价值:对业务目标的贡献;风险的降低;运营效率的提高。
有效性:目标的实现;扩展数据管理专员正在使用的相关工具;沟通的有效性;培训的有效性;采纳变革的速度
可持续性:制度和流程的执行星空;标准和规程的遵从情况
遵从法规和内部数据规范。
2.1.6、怎样写数据战略?数据战略应该包括哪些内容? #
数据治理战略界定了治理任务的范围和目标。
可以从下面几个方面写数据战略
章程:确定数据治理的业务驱动因素、愿景、使命和原则,包括准备度评估、内部流程发现和当前问题或者成功标准;
运营框架和责任:为数据治理活动定义组织架构和职责
实施路线图
规划运营目标
数据战略应该包括:
- 定义数据治理的运营框架
- 制定数据治理的目标、原则和制度
- 推动数据管理项目立项
- 参与变革管理
- 参与问题管理
- 评估法规遵从行要求
2.2、数据架构 #
2.2.1、数据架构到底包括哪些内容?输出物有哪些? #
数据架构包括:
数据分布、数据流设计、数据价值链等;
数据模型
- 概念模型
- 逻辑模型
- 物理模型
2.2.2、数据湖、数据中台、和湖仓一体 #
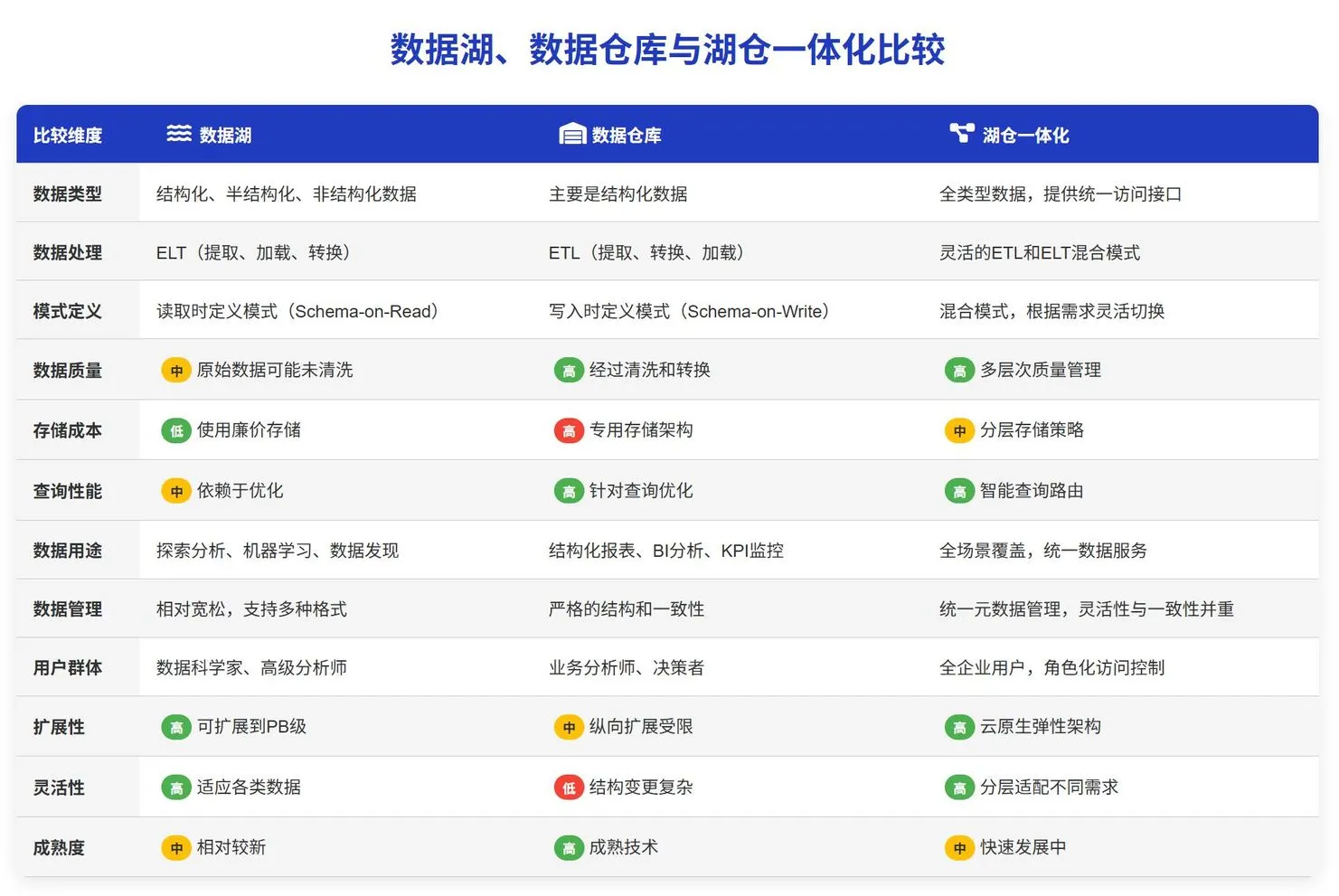
| 比较维度 | 数据湖 | 数据仓库 | 湖仓一体化 | 数据空间 | 数据中台 |
|---|---|---|---|---|---|
| 数据类型 | 结构化、半结构化、非结构化数据 | 主要是结构化数据 | 全类型数据,提供统一访问接口 | 多类型数据(本地 + 跨主体分布存储) | 全类型数据(企业内集中治理) |
| 数据处理 | ELT(提取、加载、转换) | ETL(提取、转换、加载) | 灵活的 ETL 和 ELT 混合模式 | 联邦计算(数据不动、算法 / 指令动) | 统一 ETL + 数据标准化处理 |
| 模式定义 | 读取时定义模式(Schema-on-Read) | 写入时定义模式(Schema-on-Write) | 混合模式,根据需求灵活切换 | 动态授权模式(按需确权、实时适配) | 统一数据模型(主题域 + 业务对象) |
| 数据质量 | ⚠️ 原始数据可能未清洗 | ✅ 经过清洗和转换 | ✅ 多层次质量管理 | ✅ 跨主体数据确权 + 溯源验证 | ✅ 企业级数据质量规则 + 全链路监控 |
| 存储成本 | ✅ 使用廉价存储 | ❌ 专用存储架构 | ⚠️ 分层存储策略 | ✅ 本地存储(无集中存储成本)+ 按需协同 | ⚠️ 企业级集中存储 + 计算资源投入 |
| 查询性能 | ⚠️ 依赖于优化 | ✅ 针对查询优化 | ✅ 智能查询路由 | ⚠️ 依赖跨主体网络 + 加密计算效率 | ✅ 预计算 + 缓存加速(面向业务场景) |
| 数据用途 | 探索分析、机器学习、数据发现 | 结构化报表、BI 分析、KPI 监控 | 全场景覆盖,统一数据服务 | 跨主体可信协作(如医疗 / 金融数据共享) | 企业内业务复用(指标、标签、API 服务) |
| 数据管理 | 相对宽松,支持多种格式 | 严格的结构和一致性 | 统一元数据管理,灵活性与一致性并重 | 数据主权确权 + 全链路追溯管理 | 统一元数据 + 数据资产化管理(目录 / 权限) |
| 用户群体 | 数据科学家、高级分析师 | 业务分析师、决策者 | 全企业用户,角色化访问控制 | 跨机构 / 企业的多主体用户(需身份认证) | 企业内业务人员、开发人员、分析师 |
| 扩展性 | ✅ 可扩展到 PB 级 | ⚠️ 纵向扩展受限 | ✅ 云原生弹性架构 | ✅ 原生分布式扩展(多节点无中心协同) | ✅ 企业级水平扩展(支持业务模块新增) |
| 灵活性 | ✅ 适应各类数据 | ❌ 结构变更复杂 | ✅ 分层适配不同需求 | ✅ 动态适配跨主体数据格式与协作规则 | ⚠️ 需适配企业统一模型(变更成本较高) |
| 成熟度 | ⚠️ 相对较新 | ✅ 成熟技术 | ⚠️ 快速发展中 | ⚠️ 部分场景落地(处于发展阶段) | ✅ 企业级落地成熟(主流技术栈) |
2.2.3、批流一体架构 #
概念:流批一体(或称 流批融合、统一架构)是一种同时支持批处理和流处理的架构与技术模式,强调代码复用、计算逻辑统一,兼顾实时性与准确性。
主要架构模式:
Lamada架构
1)批处理层(BatchLayer)。数据湖作为批处理层提供服务,包括近期的和历史的数据。
2)加速层(SpeedLayer)。只包括实时数据
3)服务层(ServingLayer)。提供连接批处理和加速层数据的接口。
缺点:逻辑重复(开发成本高)、维护困难
典型场景
实时 + 离线混合需求的系统
对历史数据和实时数据都需处理的 BI 系统
复杂事件处理(CEP)与周期性报表共存的场景
战略性的新型数据平台的采购和建设
- 战略性
- 数仓、数据湖、数据中台
- 信创
2.3、数据建模 #
2.3.1、不同种类的数据建模? #
数据模型方案分为:关系型、维度型、面向对象型、基于事实型、基于时序型和非关系型数据库。
数据标准应该怎么建立? #
SCD #
一些维度表的数据不是静态的,而是会随着时间而缓慢地变化,这种随着时间发生变化的维度称之为缓慢变化维,把处理维度表数据历史变化的问题,称为缓慢变化维问题,简称 SCD 问题。
解决方法:保留原始值、改写属性值、增加维度新行、增加维度新列、增加历史表、使用拉链表保存历史快照
3NF #
1)第一范式(1NF)。确保每个实体都有一个有效的主键,且每个属性都依赖于主键:消除重复组,并确保每个属性的原子性和不可再分割(不是多值的)。1NF 通过额外的实体(通常称为关联实体)来解决多对多关系。
2)第二范式(2NF)。在1NF 基础上,确保每个实体都有最小的主键,每个属性都依赖于完整的主键。
3)第三范式(3NF)。在 2NF 基础上,确保每个实体没有隐藏的主键,每个属性都不依赖于键之外的任何属性(“非主键列之间不存在依赖关系”)。
第三范式(3NF)是指在满足第二范式的前提下,如果一个非主属性仅依赖于主键而不依赖于其他非主属性,则该表符合第三范式。换句话说,非主属性之间不应存在依赖关系,而应直接依赖于主键,这样可以有效避免数据冗余和更新异常。
SuperType 和SubType #
超类型/子类型设计是一种面向对象的设计模式,它通常用于处理具有共同属性集合的一组对象。超类型是一种通用模板,它定义了属性、方法和行为,而子类型是超类型的特定实现,可以继承超类型的属性和方法并追加、修改或重写它们以满足其独特的需求。
例如,假设我们有一个汽车制造商,他们生产各种类型的车,例如轿车、卡车和摩托车。每种车都有一些共同的属性,例如车身颜色、发动机类型、最大速度等。我们可以使用超类型/子类型设计来创建一个超类型,它包含所有共同属性,并创建子类型以处理每种车的特定属性和需求。
OLTP 和 OLAP 的不同点在什么地方? #
| 对比项 | OLTP | OLAP |
| 面向应用 | 日常交易处理 | 查询、分析、决策 |
| 访问模式 | 简单小事务、操作少量数据 | 复杂查询,大量数据 |
| 数据 | 当前最新数据 | 历史数据 |
| 数据规模 | GB | TB-PB |
| 数据更新 | 实时 | 批量 |
| 数据存储 | 满足3NF | 反范式,星型模型 |
| 用户 | 操作人员、低层管理人员 | 决策人员,高级管理人员 |
| DB设计 | 面向应用 | 面向主题 |
| 软件技术 | 数据库 | 数据仓库 |
MOLAP 还是ROLAP #
ROLAP 是指关系数据的关系在线分析处理。
MOLAP 被称为多维在线分析处理,它通过多个数据维度来实现。
ROLAP 是 关系型 OLAP
其中数据以传统方法排列,如数据仓库中的行和列。它以多维形式对用户可见和访问。为了将其显示为多维视图,数据被设计为支持数据收集和存储的元数据的相关层。它动态地处理复杂的查询。它比 MOLAP 慢,其中 ROLAP 以更高的速度处理大量数据。
MOLAP 是一种多维 OLAP
其中在注册系统上分析数据。数据排列在多维数组中。在数据库管理中加载数据时,该数组携带预定义的数据。MOLAP 系统是在应用层实现的,当用户发送任何请求时,它以最短的响应时间获取数据。
关系模型的表达能力不包括创建特定数据类型的维度和度量主题。基本元素包括完整性、属性、关系,主要应用于星型模式。
ROLAP 使用 SQL 作为其功能语言来获取数据并对其进行处理,而MOLAP 使用稀疏矩阵技术以多维数据立方体的形式从多维数组中获取数据。
ROLAP 响应时间慢,因为它显示任何数据的多维形式,但 MOLAP 非常快,因为它不显示任何多维视图。
ROLAP 和 MOLAP 都处理复杂的查询,并有其独特的性能。如果用户想要任何快速响应系统,他可以采用 MOLAP
| 对比 | ROLAP | MOLAP | HOLAP |
| 首字母缩略词 | 关系在线分析处理 | 多维在线分析处理 | 混合在线分析处理 |
| 储存方法 | 数据存储在主数据仓库中 | 数据存储在注册数据库MDDB上 | 数据存储在关系数据库中 |
| 获取方法 | 从主存储库获取数据 | 从专有数据库中获取数据 | 从关系数据库中获取数据 |
| 数据整理 | 数据以带有行和列的表格形式排列和保存 | 数据以数据立方体的形式排列和存储 | 数据以多维形式排列 |
| 体积 | 处理大量数据 | 处理保留在专有中的有限数据 | 可处理大数据 |
| 技术 | 它适用于 SQL | 它适用于稀疏矩阵技术 | 它同时使用稀疏矩阵技术和 SQL |
| 设计意图 | 动态访问 | 静态访问 | 动态访问 |
| 响应时间 | 它具有最大响应时间 | 它具有最短响应时间 | 需要最短的响应时间 |
如何来选择和建立实体? #

在逻辑模型的基础上,物理模型的开发还需要做哪些工作? #
解决逻辑抽象、添加属性细节、添加属性引用对象、指定代理键、逆范式化、建立索引、建立分区、创建视图
如何解决SCD问题 #
解决方法:保留原始值、改写属性值、增加维度新行、增加维度新列、增加历史表、使用拉链表保存历史快照
哪里可以找到各种建模标准 #
1)数据建模和数据库设计的标准交付成果的清单和描述。
2)适用于所有数据模型对象的标准名称,可接受英文缩写和非常见单词的缩写规则列表。
3)所有数据模型对象的标准命名格式列表,包括属性命名和列命名。
4)设计和维护交付成果的标准方法的列表和描述。
5)数据建模和数据库设计角色和职责的列表和描述。
6)数据建模和数据库设计中涉及的所有元数据属性的列表和描述,包括业务元数据和技术元数据。例如,准则可以设定数据模型中包含的每个属性的预期血缘关系展现内容。
7)元数据质量期望和要求(见第13章)。
8)使用数据建模工具的准则。
9)准备和指引设计评审的准则。
10)数据模型版本管理的指导原则。
11)禁止或需要避免的事项列表。
2.4 数据安全 #
国家相关法律
《国家安全法》、《网络安全法》、《数据安全法》、《个人信息保护法》
数据分类分级
数据跨境
数据安全的核心内容
数据安全和数据交易
隐私计算
全方位的数据安全管理包括哪些内容
chatGPT有哪些可能的数据安全和合规问题?如何解决?
数据安全制度应该有哪些内容?数据安全细则应该有哪些内容?
2.5 主数据 #
数据分散、且标准不统一、大量不一致,相互覆盖、质量不高、主责部门不清、新增变更流程不明确等问题,从而严重影响客户主数据的应用。
数据标准和主数据的关系 #
数据标准是 “规则”,主数据是 “核心数据实体”;数据标准定义主数据的 “如何管、如何用”,主数据体现数据标准的 “落地效果”。
| 维度 | 数据标准 | 主数据 |
|---|---|---|
| 核心定义 | 企业统一制定的、约束数据全生命周期的 “规则集合”(格式、口径、质量、安全等) | 企业核心业务实体的 “基准数据”(唯一、稳定、跨系统共享),是业务活动的基础载体 |
| 本质属性 | 规范性、制度性(“数据的法律 / 标准”) | 实体性、基础性(“数据的核心资产”) |
| 覆盖范围 | 所有数据类型(主数据、交易数据、参考数据、元数据等) | 特定核心实体(客户、供应商、产品、物料、组织架构等) |
| 核心目标 | 统一数据的 “语言规则”,确保数据的一致性、准确性、合规性 | 统一核心实体的 “唯一视图”,消除数据冗余、冲突,支撑跨系统协同 |
| 典型示例 | 客户编号格式为 “C+8 位数字”、产品名称禁止特殊字符、订单状态枚举值规范 | 黄金客户档案、统一产品目录、集团组织架构清单 |
主数据如何识别 #
主数据的识别是主数据管理(MDM)的起点,核心逻辑是:筛选出企业内跨系统、跨业务、长期稳定且对核心业务运转至关重要的 “基准实体数据”.结合业务属性、技术特征、管理需求三维度
1、实体:是否共享。
2、属性:重要的或相对稳定的属性。
3、最大公约数原则。
主数据如何建设 #
1、识别驱动因素和业务需求。
2、评估和评价数据源。
3、定义架构方法。
4、建模主数据。
5、定义管理职责和维护流程。
6、建立治理制度;推动主数据使用。
对于存量系统,如何落地主数据标准体系? #
主数据工具应该有哪些功能? #
数据整合工具、数据修复工具、操作型数据库(ODS)、数据共享中心(DSH)或专门的主数据管理应用。
主数据管理工具通常包括主数据建模、主数据采集、主数据管理、主数据查询/共享等功能。
主数据管理的大概活动和过程有哪些? #
1、定义驱动因素和需求
2、评估和评估数据源
3、定义架构方法
4、建模数据
5、定义管理和维护流程
6、制定治理制度
7、实现数据共享/集成服务
- 获取共享数据源
- 发布参考数据和主数据
2.6 数仓和BI #
Inmon 和 Kimball 关于数仓的差别有哪些? #
关系型二维表,矩阵型多维
Inmon强调整体规划和数据质量,但建设周期长;Kimball注重快速交付和查询性能,但存在冗余风险。
| 对比维度 | Inmon(自上而下) | Kimball(自下而上) |
| 建模思想 | 企业级统一建模 | 业务驱动的维度建模 |
| 数据组织 | 第三范式 | 星型模型 / 雪花模型 |
| 架构模式 | ODS →EDW→数据集市 | 数据集市→数据仓库 |
| 一致性 | 强,企业级统一 | 弱,可能存在冗余 |
| 建设周期 | 长,投入大 | 短,快速见效 |
| 使用场景 | 大型集团,跨部门分析 | 中小企业,业务快速迭代 |
| 优势 | 数据标准化,质量高 | 查询性能好,贴近业务需求 |
| 劣势 | 建设慢、成本高 | 荣誉多,难以全局整合 |
数仓的主要组件内有哪些? #
核心组件包括:源系统、数据集成、数据存储区域、ODS、数据集市、数据立方体
源系统:将要接入数据仓库/商务智能环境的数据。包括CRM、财务系统、人力资源等业务系统;还包括来自供应商和外部来源数据,以及DaaS、网页内容和各种大数据计算结果。
数据集成:包括ETL(ETL过程负责从数据源中提取数据,进行必要的转换和清洗,然后加载到数据仓库中)、数据虚拟化及将数据转化成统一格式并放置到统一位置的其他技术。
数据存储区域:数据仓库包括数据暂存区、参考数据和主数据一致性维度、中央数据仓库。
ODS:操作型数据存储是中央数据仓库持久化存储的某个数据来源副本,支持更低的延迟。操作型数据存储仅包含某个时间窗口的数据,不是全部历史记录。
数据集市:数据集市是一种数据存储类型,通常用于支持数据仓库环境的展示层,也用于呈现数据仓库的部门级或功能级子集。
数据立方体:主要有3种支持OLAP的经典模式:关系型、多维性及混合型。
数据分析的自助服务是什么? #
自助服务是商务智能产品组合中的一个基本交付方式。自助服务一版是在受管理的门户中引导用户活动,根据用户的权限提供多种功能,包括消息传递、报警、查看预定的生产报表、与分析报表互动、开发即席报表,以及仪表盘和积分卡等。
问数服务
数仓、数据湖、数据中台、数据空间的相同点和不同点有哪些? #
| 对比项 | 数据仓库 | 数据中台 | 数据湖 | 数据空间 |
| 存储结构 | 主题式 | 平面 | 平面 | 分布式(去中心化) |
| 存储方式 | 结构化 | 结构化 | 非结构化 | 多类型(结构化/非结构化,本地存储) |
| 实时支持 | 历史分析 | 实时分析 | 实时分析 | 事实协同计算 |
| 是否预定义 | 需要 | 需要 | 不需要 | 动态定义(按需授权) |
| 安全和权限 | 高 | 高 | 一般 | 极高(加密/确权/追溯) |
| 分布式支持 | 不支持 | 支持 | 支持 | 原生支持(多节点协同) |
| 技术成熟度 | 成熟 | 成熟 | 不成熟 | 发展中 |
数仓的数据湖的架构图应该是怎么样的? #

数仓的一些疑难问题,比如SCD、星型和雪花模型的融合等?
指标体系 #
指标口径清晰、统一规范;支持用户的自助灵活用数;有效控制报表开发成本;
保障指标合理落地加工实施。
实现指标应用,满足不同类型用户需求
建设指标长效管理机制,推动指标体系完善。
数据体系的核心,连接基础数据和数据应用的桥梁。
数仓建设的主要活动 #
理解需求 #
- 考虑业务目标和业务战略
- 确定业务领域并框定范围
- 访谈,了解业务人员需求,问题及访问的数据
- 掌握关键指标和计算口径
定义和维护DW和BI架构 #
- 确定数据仓库/商务智能技术架构
- 确定数据仓库/商务智能管理流程
开发数据仓库和数据集市 #
- 建立源到目标的映射关系
- 修正和转换数据
加载数据仓库 #
- 工作量最大的部分
- 延迟要求、源可用性、批处理时间窗口
- 数据质量问题
实施BI产品组合 #
- 根据需要对用户进行分组
- 将工具与用户要求匹配
维护数据产品 #
- 发布管理
- 管理数据产品开发声明周期
- 监控和调优加载过程
- 监控和调优商务智能活动和性能
2.7 元数据 #
2.7.1 应该从哪里去梳理和收集元数据?特别是数仓的元数据应该怎样梳理? #
应用程序中元数据存储库;业务术语表;商务智能工具;配置管理工具;数据字典;数据集成工具;数据库管理和系统目录;数据映射管理工具;数据质量工具;字典和目录等
元数据梳理:
业务元数据、技术元数据、操作元数据
业务元数据:每段ETL、表背后的归属业务主题;
业务描述:每段代码实现的具体业务逻辑
标准指标:类似于BI中的语义层、数仓中的一致性事实;
标准维度:通标准指标,对分析的各个维度定义实现规范化、标准化。
技术元数据:可以从数据源元数据、ETL元数据、数据仓库元数据、BI元数据。
操作元数据:错误日志、服务水平协议的要求和规定;数据归档、保留规则和相关归档文件。
2.7.2 怎么应用元数据? #
数据仓库与数据湖管理,记录数据的来源、结构和质量,帮助实现数据的整合和管理
数据库管理:元数据描述数据库的结构、表、字段等信息,帮助数据管理员优化行呢个和维护数据库。
元模型是什么? #
元模型是一个元数据存储库的数据模型。定义元数据战略和理解业务需求的第一个设计步骤。可以根据需要开发不同级别的元模型;高级别的概念模型描述了系统之间的关系,低级别的元模型细化了各个属性。作为一种规划工具和表达需求的方案,元模型本身也是有价值的元数据源。
数据资产目录和元数据目录是什么关系? #
数据资产目录不等于元数据目录。
数据资产目录建立在元数据基础之上。
元数据上线后如何维护? #
1、明确维护责任与流程:
角色分工,标准化维护流程
2、核心维护内容和策略
技术元数据维护:自动同步为主,手动修正为辅
业务元数据维护:业务术语标准化;指标元数据动态更新
操作元数据维护:聚焦数据访问日志、任务余小宁状态、SLA达成情况。
分类与标签维护
3、监控与异常处理
建立元数据监控体系:自动监控指标;告警机制
异常处理流程:缺失类异常;错误类异常;冲突类异常
4、定期审计:周期性审计
元数据系统应该具有哪些功能? #
元数据系统覆盖元数据采集、存储、管理、应用、治理全流程。
1、核心基础功能:
1.1 多源元数据采集功能
1.2 元数据存储与管理:统一元数据模型、版本管理、存储能力
1.3 元数据检索与查询
2、核心治理功能
数据血缘分析功能:血缘类型、可视化能力、血缘精度
数据分类与标签管理功能:标签体系管理、标签赋值、标签应用
业务术语与指标管理功能:业务术语库、指标管理、数据字典
3、运维与治理支撑
监控与告警功能、权限与安全管理功能、工作流与审批功能;
4、高级应用功能
数据影响分析、智能推荐与辅助功能、集成与开放能力
如果元数据没有管理好,会怎样? #
- 冗余的数据和数据管理流程
- 重复和冗余的数据字典、元数据促成农户库和其他元数据存储
- 不一致的数据元素定义和与数据滥用相关的风险
- 元数据的不同来源和版本之间互相矛盾冲突,降低了数据使用者的信心
- 元数据和数据的可靠性受到质疑。
元数据应该包括数据的哪些属性? #
数据质量和数据安全属性
一、基础标识属性(所有元数据通用)
用于唯一识别元数据对象,是元数据管理的基础:
唯一 ID:系统分配的全局唯一标识(如数据表 ID、指标 ID),避免重名混淆;
名称:元数据对象的业务 / 技术名称(如 “用户订单表”“order_table”“GMV 指标”);
别名 / 简称:便于日常使用的简化名称(如 “日活” 代指 “日活跃用户数指标”);
类型:元数据对象的分类(如表 / 字段 / 指标 / 术语 / ETL 任务);
状态:当前生命周期状态(草稿 / 生效 / 失效 / 归档);
创建时间 / 更新时间:元数据的创建及最后修改时间;
负责人 / 所属团队:业务 / 技术责任人及归属部门(如 “订单表负责人:张三,所属零售业务部”)。
集团数字化转型应该从哪个领域开始? #
应该从元数据开始