安装Ollama
Ollama 可以通过多种方式安装,甚至可以在 Docker 容器中运行。在 GPU(Nvidia、AMD、Intel)上运行时,Ollama 会明显更快,但它可以在 CPU 和 RAM 上运行。要在没有任何其他先决条件的情况下安装 Ollama,您可以按照他们的安装程序进行作:
安装程序完成后,如果你使用的是 Windows,你应该会在开始菜单中看到一个条目来运行它:
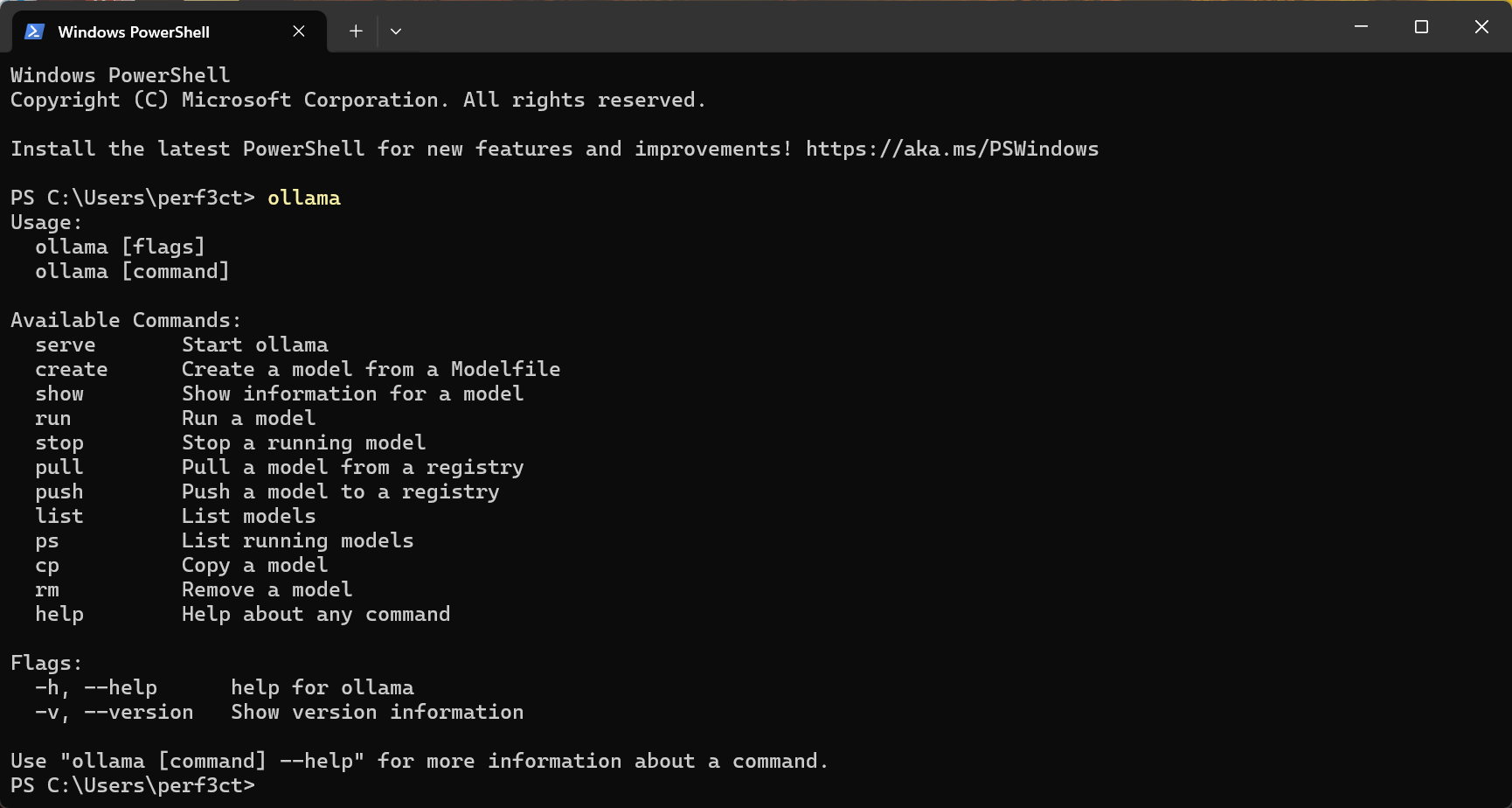
此外,您应该可以通过 Powershell 或 CMD 访问 CLI:ollama
安装 Ollama 后,您可以继续使用和运行要使用的模型。这是一个命令,用于拉取截至 2025 年 4 月我最喜欢的工具兼容模型和嵌入模型:pull
ollama pull llama3.1:8b
ollama pull mxbai-embed-large此外,您可以通过转到 http://localhost:11434 来确保它正在运行,您应该会得到以下响应(端口 11434 是“正常”Ollama 端口):
现在您已经启动并运行了 Ollama,并提取了一些模型,您可以继续使用 Ollama 作为聊天提供程序和嵌入提供程序!