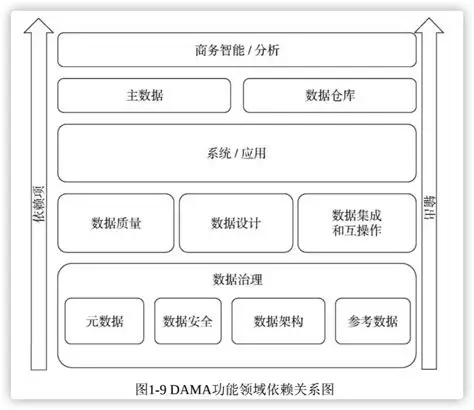
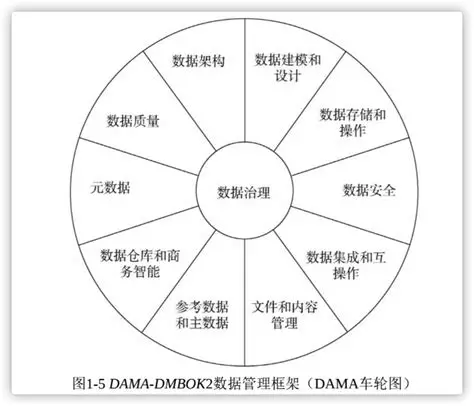

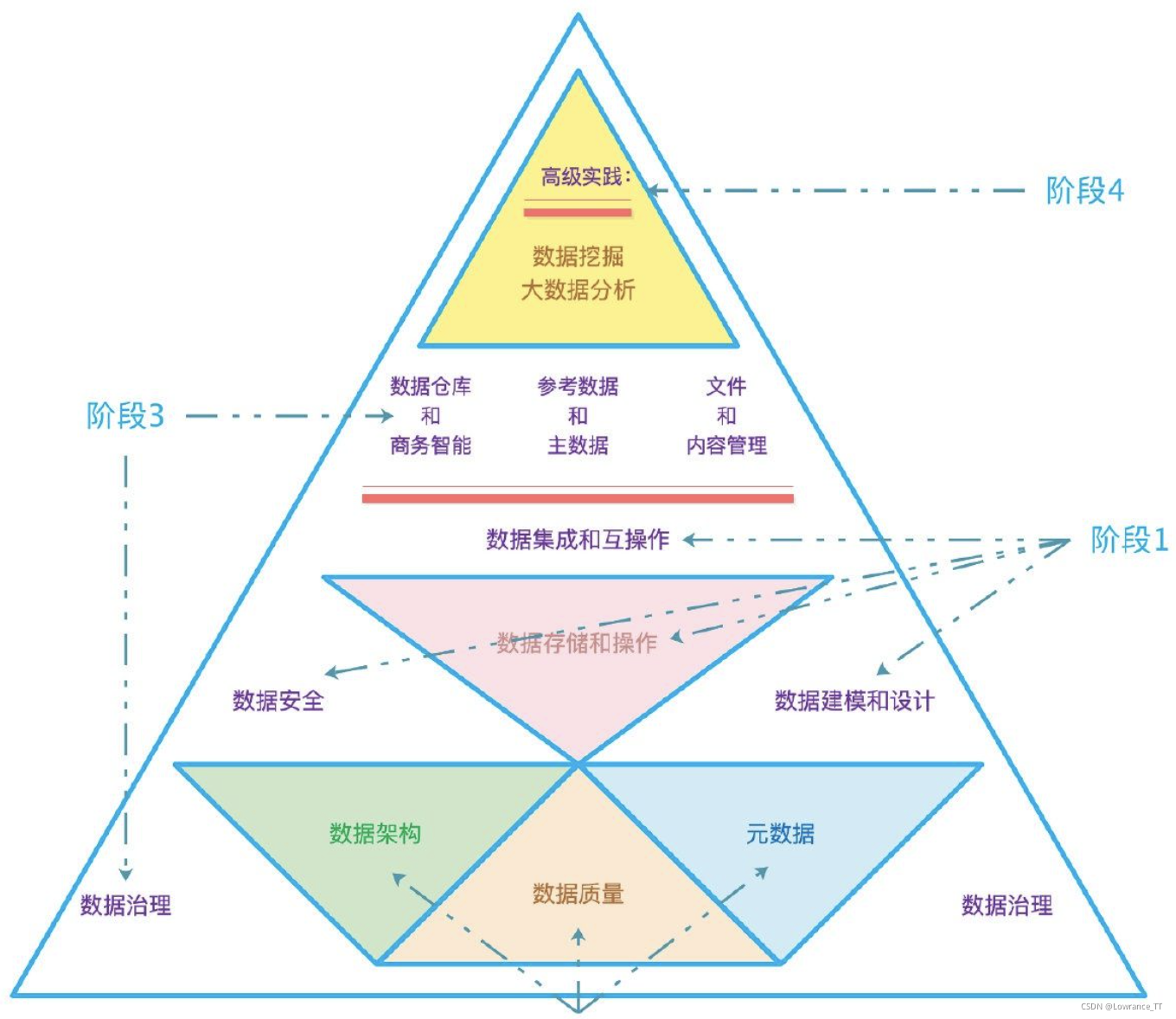
企业数据模型(EDM)

模式(Scheme)与表示法
| 模式 | 示例表示法 |
| 关系 | 信息工程 信息建模集成定义(IDEF1X) 巴克表示法 陈氏表示法 |
| 维度 | 维度 |
| 面向对象 | 统一建模语言(UML) |
| 基于事实 | 基于实时的对象角色建模(ORM或ORM2) 完全面向通信的建模(FCO-IM) |
| 基于时间 | Data Vault 锚建模 |
| NoSQL | 文档 列 图 键值 |
模式(Scheme)与数据库类型
关系与基于事实是一样的。它在关系数据中可以建3种模型(CDM、LDM、PDM)在其他数据库中,可以建两种数据模型(LDM、CDM)
维度和面向对象的数据库,可以在关系数据中建三种模型(CDM、LDM、PDM)也可以在自己的数据库种建三种模型(CDM、LDM、PDM)
基于时间和NoSQL数据库只能建PDM,不能在关系与多维度数据库种建模型。
| 模式 | 关系数据库管理系统 | 多维数据库管理系统 | 对象数据库 | 文档数据库 | 列式数据库 | 键值内存数据库 |
| 关系 | CDM、LDM、PDM | LDM、CDM | LDM、CDM | LDM、CDM | LDM、CDM | LDM、CDM |
| 维度 | CDM、LDM、PDM | CDM、LDM、PDM | ||||
| 面向对象 | CDM、LDM、PDM | CDM、LDM、PDM | ||||
| 基于事实 | CDM、LDM、PDM | LDM、CDM | LDM、CDM | LDM、CDM | LDM、CDM | LDM、CDM |
| 基于时间 | PDM | |||||
| NoSQL | PDM | PDM | PDM | PDM |
数据模型记分卡
测量数据模型质量的方法有多种,并且都需要一个比较标准它提供11个数据模型质量指标:构成记分卡的10个。
| # | 类别 | 总分数 | 模型分数 | % | 注释 |
| 1 | 模型捕获需求的程度如何? | 15 | |||
| 2 | 模型有多完整? | 15 | |||
| 3 | 模型与其方案匹配程度如何? | 10 | |||
| 4 | 模型结构上如何合理? | 15 | |||
| 6 | 模型遵循命名标准的方式如何? | 5 | |||
| 7 | 模型在可读性仿麦呢安排的如何? | 5 | |||
| 8 | 定义有多好? | 10 | |||
| 9 | 模型与企业的一致性如何? | 5 | |||
| 10 | 元数据与数据的匹配程度如何? | 10 | |||
| 总分数 | 100 |
云计算XaaS

DW/BI-企业信息工厂(CIF)架构
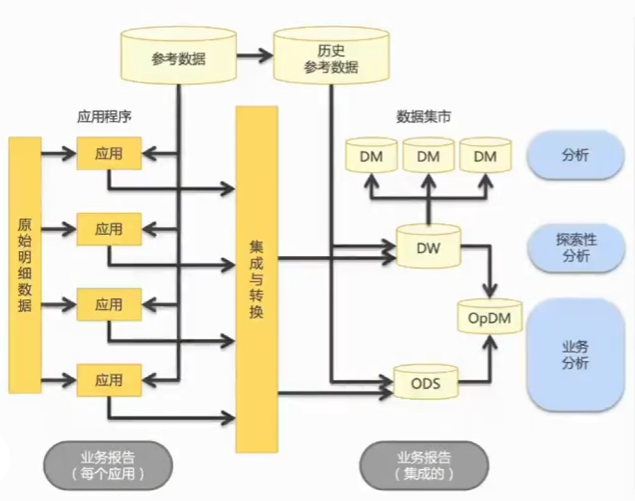
Bill Inmon的企业信息工厂(Corporate Information Factory, CIF)是两种主要的数据仓库建设模式之一。(因蒙) Inmon关于数据仓库的组成是这样描述的: “面向主题的、 整合的、 随时间变化的、 包含汇总和明细的、 稳定的历史数据集合”。
1) 面向主题的。 数据仓库是基于主要业务实体组织的, 而不关注功能或应用。
2) 整合的。 数据仓库中的数据是统一的、 内聚的。 保持相同的关键结构, 结构的编码和解码、 数据定义和命名规范在整个仓库中都是一致的。 因为数据是整合的, 数据仓库不是简单的运营数据的副本。 相反, 数据仓库变成了一个数据记录的系统。
3) 随时间变化的。 数据仓库存储的是某个时间段的数据。 数据仓库中的数据像快照一样, 每一张快照都反映了某个时点的数据状态。 这意味着基于某个时间段的数据查询总是得到相同的结果, 无论什么时候去查询。
4) 稳定的。 在数据仓库中, 数据记录不会像在业务系统里那样频繁更新。 相反, 新数据只会追加到老数据的后面。 一组记录可以代表同一个交易的不同状态。
5) 聚合数据和明细数据。 数据仓库中的数据包括原子的交易明细, 也包括汇总后的数据。 业务系统很少聚合数据。 数据仓库一旦建好, 出于成本和空间的考虑, 都会有把数据汇总的需求。 在当前的数据仓库环境中, 汇总数据可以是持久地存在一个表里, 也可以是非持久的、 以视图的形式展现。 汇总数据是否持久化的决定因素通常是性能上是否需要。
6) 历史的。 业务系统的重心是当前的数据。 数据仓库还包括历史数据, 通常要消耗很大的存储空间。
CIF架构
1) 应用程序。 应用程序处理业务流程。 应用程序产生的明细数据流转到数据仓库和操作型数据存储中, 继而用作分析。
2) 数据暂存区。 介于业务系统源数据库和目标数据仓库之间的一个数据库。 暂存区是用于数据抽取、 转换和加载的地方, 对最终用户透明。 暂存区中的大部分数据是短时留存的, 通常只有相当少的一部分数据是持久性数据。
3) 集成和转换。 在集成层, 来自不同数据源的数据被转换整合为数仓和ODS里的标准企业模型。
4) 操作型数据存储(ODS) 。 操作型数据存储是业务数据的集成数据库。 数据可能直接来源于应用系统, 也可能来自其他数据库。 操作型数据存储中通常包括当前的或近期的(30~90天) 数据, 而数据仓库还包含历史(通常是很多年的) 数据。 操作型数据存储的数据变化较快, 而数据仓库的数据相对稳定。 不是所有的组织都会建设操作型数据存储, 操作型数据存储的存在满足了企业对低延迟数据的需求。 操作型数据存储可以作为数据仓库的主要来源, 还可用于对数据仓库做审计。
5) 数据集市。 数据集市为后续的数据分析提供数据。 这里说的数据通常是数据仓库的子集, 用于支持特定分析或特定种类的消费者。 例如, 数据集市可以聚合数据, 以支持更快的分析。 多维模型(用反范式的技术) 通常针对面向用户类型的数据集市。
6) 操作型数据集市(OpDM) 。 操作型数据集市是专注于运营决策支持的数据集市。 它直接从操作型数据存储而不是从数据仓库获取数据, 具有与操作型数据存储相同的特性: 包含当前或近期的数据, 这些数据是经常变化的。
7) 数据仓库。 数据仓库为企业数据提供了一个统一的整合入口,以支持管理决策、 战略分析和规划。 数据从应用程序系统和操作型数据存储流入数据仓库, 然后流到数据集市, 这种流动通常只是单向的。 需要更正的(不符合要求的) 数据将被拒绝进入, 理想情况是在其源头系统完成更正, 然后通过ETL流程系统重新加载。
8) 运营报告。 运营报告从数据存储中输出。
9) 参考数据、 主数据和外部数据。 除了来自应用程序的交易数据, 企业信息工厂还包括理解交易所需的数据, 如参考数据和主数据。对通用数据的访问简化集成在数据仓库中。 当应用程序使用当前的参考数据和主数据时, 数据仓库还需要它们的历史值及其有效的时间范围
DW/BI-维度数据仓库(DDW)架构
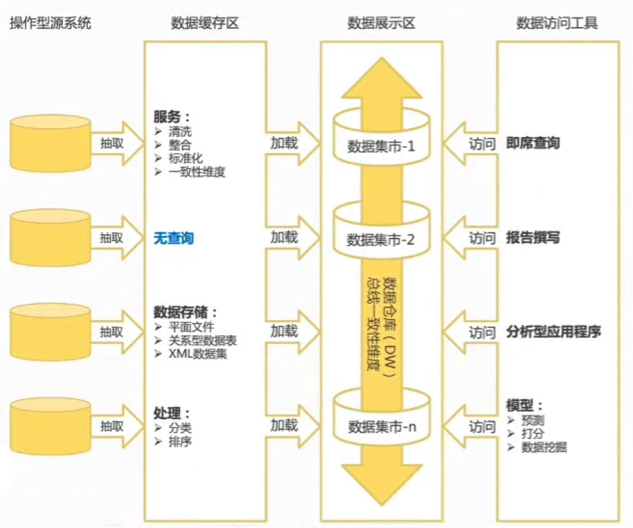
Kimball的数据仓库比Inmon的数据仓库的可扩展性更强。数据仓库包含数据暂存和数据展示区域的所有组件。
1) 业务源系统。 企业中的操作型/交易型应用程序。 这些应用程序产生数据, 数据再被集成到操作型数据存储和数据仓库中。 此组件等同于企业信息工厂图中的应用程序系统。
2) 数据暂存区域。 Kimball的暂存区域包括需要集成的流程和用于展示的转换数据, 可以与企业信息工厂的集成、 转换和数据仓库组件的组合进行类比。 Kimball的重点是分析类数据的高效终端交付, 比Inmon的企业管理数据范围要小。 Kimball的企业数据仓库可以适配数据暂存区域架构。
3) 数据展示区域。 与企业信息工厂中的数据集市类似, 关键的架构差异在于“数据仓库总线”的集成范式, 如应用于若干个数据集市的共享或一致的维度。
4) 数据访问工具。 Kimball方法侧重于最终用户的数据需求。 这些需求推动采用适当的数据访问工具
CDC(变更数据捕获)技术差异,很重要
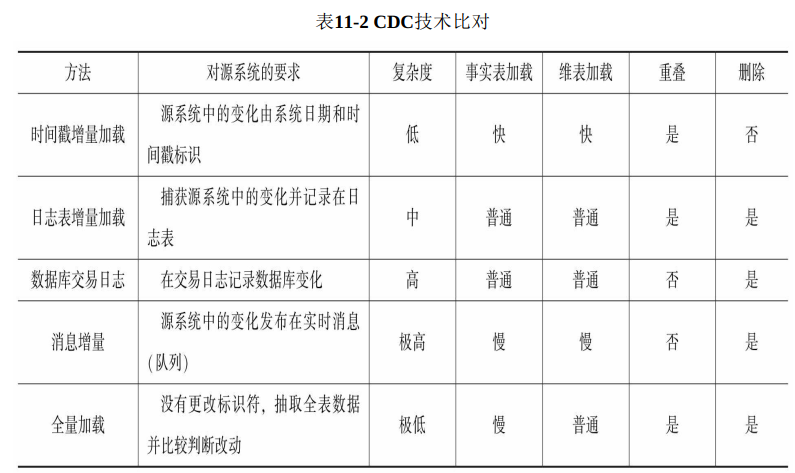
表中总结了CDC(变更数据捕获)技术之间的差异包括其相对复杂性和速度。
重叠列标识源系统变更和目标环境之间是否存在数据重复。
当“重叠”为“是”时,此变更数据可能已经存在。当“删除”指示器设置为“是”时,变更数据方法将跟踪源系统中发生的任何删除操作(对于过期的维度不再使用时非常有用)。
当源系统未跟踪“删除”时,需要进行其他工作来确定何时发生删除操作。
DW/BI - 发布管理(不重要)
概念性DW / BI 和大数据架构



